
Spring Data JPA
Spring Data JPA
Spring Data JPA를 사용하면 JPA 기반 Repository를 쉽게 구현할 수 있다.
인터페이스만 작성을 하면 Spring이 자동으로 구현을 해주기 때문에 반복적인 작업이 상당히 줄어든다.
특징으로는 다음과 같다.
- Spring 및 JPA 기반 Repository를 위한 복잡한 기능을 지원한다.
- Querydsl을 통한 type-safe한 JPA 쿼리를 제공한다.
- DomainClassConverter를 통해 domain 클래스를 적절하게 변환해준다.
- 페이징 처리, 동적 쿼리 실행의 추상화로 간단히 쓸 수 있다.
- @Query주석이 달린 쿼리의 유효성 검사를 실행한다.
- XML기반 엔티티 매핑도 지원한다.
- @EnableJpaRepositories로 JavaConfig 기반 Repository를 구성한다. (SpringBoot에서는 어노테이션 없이 사용 가능하다.)
Getting Start Spring Data JPA
1. 프로젝트 세팅
1-1 Spring
- pom.xml에 spring-data-jpa와 h2 database의 의존성을 추가한다.
- xml 또는 java config 로 base-package를 지정한다.
😊root-context.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/data/jpa
https://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<jpa:repositories base-package="com.test.repositories" />
</beans>
jpa:repositories 패키지의 하위 패키지에 있는 JPARepository를 인식한다.
(boot는 SpringBootApplication이 기본 JPARepository 패키지)
😊ApplicationConfig.java
@Configuration
@EnableJpaRepositories
@EnableTransactionManagement
class ApplicationConfig {
@Bean
public DataSource dataSource() {
EmbeddedDatabaseBuilder builder = new EmbeddedDatabaseBuilder();
return builder.setType(EmbeddedDatabaseType.HSQL).build();
}
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory() {
HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter();
vendorAdapter.setGenerateDdl(true);
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(vendorAdapter);
factory.setPackagesToScan("com.test.entity");
factory.setDataSource(dataSource());
return factory;
}
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
JpaTransactionManager txManager = new JpaTransactionManager();
txManager.setEntityManagerFactory(entityManagerFactory);
return txManager;
}
}
@EnableJpaRepositories : xml의 <jpa:repositories> 와 동일기능. 해당 패키지 하위의 패키지를 JpaRepository로 인식한다.
entityManagerFactory의 리턴 객체로 LocalContainerEntityManagerFactoryBean를 사용해야 한다. (EntityManagerFactory 생성 외에도 예외 변환 매커니즘에 사용되기 때문에)
👍TIP
기본적으로 JPA repository는 Spring Bean이고 싱글톤이며 애플리케이션 로딩 시점에 초기화 된다.
로딩 시점에 검증, 메타데이터 분석 (구현체 자동생성) 을 한다.
EntityManagerFactory는 생성시 시간이 오래 걸리기 때문에 Spring Framework의 백그라운드 스레드에서 동작한다.
이를 효과적으로 활용하려면 JPA저장소를 가능한 한 늦게 초기화 해야 한다.
👍TIP : Bootstrap Mode Spring Data JPA 2.1부터 Bootstrap Mode 모드를 지원한다. 아래 3가지 변수를 지정 할 수 있다.
- DEFAULT (default) : @LAZY 달지 않는 한 실제 객체를 가져온다.
- LAZY : 모든 Repository의 Bean에게 LAZY를 선언하고 프록시 객체가 주입되도록 한다.
- DEFERRED : 기본적으로 작동방식은 LAZY랑 비슷하지만 ContextRefreshedEvent 할 때 저장소 초기화 트리거에서 검증한다. (애플리케이션 로딩 전에 검증한다.)
1-2 Spring Boot
spring boot는 기본설정이 되어있기 때문에 의존성만 추가하면 된다.
pom.xml에 spring-data-jpa와 h2 database의 의존성을 추가한다.
😊참고 제 프로젝트 세팅
spring-boot setting
2. 엔티티 관계 설정
기본적인 엔티티를 추가한다.
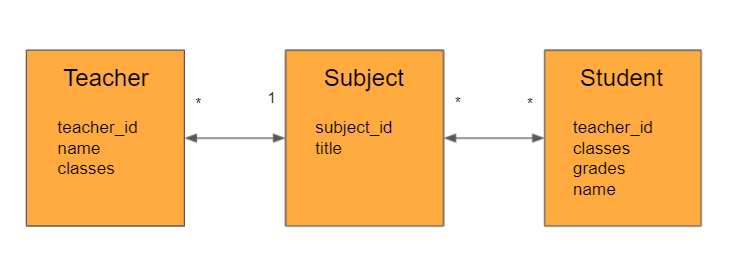
😊Teacher.java
@Entity
public class Teacher {
@Id
@GeneratedValue
@Column(name = "teacher_id")
private Long id;
private String name;
private int age;
@ManyToOne(fetch = LAZY)
@JoinColumn(name = "subject_id")
private Subject subject;
// getter,setter,Constructor •••
}
😊Subject.java
@Entity
public class Subject {
@Id @GeneratedValue
@Column(name = "subject_id")
private Long id;
private String title;
@OneToMany(mappedBy = "subject")
private List<Teacher> teacherList = new ArrayList<>();
// getter,setter,Constructor •••
}
3. 인터페이스 설정
Entity를 만들었으면 JpaRepository를 상속받는 인터페이스를 만들어보자.
그 인터페이스에 규칙에 맞는 메서드 명만 지으면 구현은 Spring이 해준다.
(작동원리는 다음 장에서 알아보자!)
😊TeacherRepository.java
public interface TeacherRepository extends JpaRepository<Teacher, Long> {
Teacher findById(long id);
List<Teacher> findByNameContains(String name); // name을 포함하는 Teacher List 리턴
}
😊Test.java
@Test
void 이름으로찾기() {
List<Teacher> teachers = teacherRepository.findByNameContains("teacher");
for (Teacher teacher : teachers) {
System.out.println("teacher = " + teacher);
}
Assertions.assertThat(teachers.size()).isEqualTo(2);
}
🔑query
-- JPQL
select
generatedAlias0
from
Teacher as generatedAlias0
where
generatedAlias0.name like :param0 escape :param1
-- SQL
select
teacher0_.teacher_id as teacher_1_1_,
teacher0_.age as age2_1_,
teacher0_.name as name3_1_,
teacher0_.subject_id as subject_4_1_
from
teacher teacher0_
where
teacher0_.name like ? escape ?
💻console
// 이름에 teacher만 있는 teacher조회
teacher = Teacher(id=4, name=teacherA, age=50, subject=Subject(id=1, title=math))
teacher = Teacher(id=5, name=teacherB, age=33, subject=Subject(id=2, title=english))
Note:
JpaRepository의 자동구현 기능을 사용하려면 @EnableAutoConfiguration 의 하위 패키지여야 한다.
(springBoot는 @SpringBootApplication 하위 패키지면 된다)
JPA Repository Function
1. Query Creation
위의 예제에서 findByNameContains() 메서드 구현 방법이다.
JPARepository 인터페이스만 상속받고 지정된 메서드명만 선언하면 구현은 Spring에게 할당하는 방식이다.
쿼리를 아예 작성 안 해도 Spring이 해주기 때문에 편리하나 기본적인 쿼리 위주로 사용한다.
👍TIP : 이름 전략 : find•••By~ (•••에는 아무거나 들어가도 된다.)
공식문서 : 이름 규칙
| Keyword | Sample | JPQL snippet |
|---|---|---|
| Distinct | findDistinctByLastnameAndFirstname | select distinct … where x.lastname = ?1 and x.firstname = ?2 |
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is, Equals | findByFirstname, findByFirstnameIs, findByFirstnameEquals |
… where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull, Null | findByAge(Is)Null | … where x.age is null |
| IsNotNull, NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection ages) | … where x.age not in ?1 |
| True | findByActiveTrue() | … where x.active = true |
| False | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstname) = UPPER(?1) |
2. Named Query
named Query는 로딩시점에 EntityManager에 쿼리를 저장한다. 실행 시 해당 쿼리를 구성하여 실행 할 수 있다.
- 정적 쿼리를 미리 지정해서 사용할 수 있다.
- 애플리케이션 로딩 시점에 문법 오류를 확인 할 수 있다.
😊Teacher.java
@Entity
@NamedQuery(
name = "Teacher.findByName",
query = "select t from Teacher as t where t.name = :name"
)
@NamedNativeQuery( // Native 쿼리도 가능하다.
name = "Teacher.findNativeByName",
query = "select name from Teacher where name = :name"
)
public class Teacher {
•••
NamedQuery는 관례상 엔티티명.메소드명을 적어주는것이 좋다. (Spring Data JPA에서 자동으로 찾아간다.)
위와 같이 선언하면 JPA에서는 아래와 같이 사용 할 수 있다.
😊Test.java
@Test
void namedQueryInJpa() {
List<Teacher> teachers =
em.createNamedQuery("Teacher.findByName",Teacher.class)
.setParameter("name","teacherA")
.getResultList();
assertThat(teachers.size()).isEqualTo(1);
assertThat(teachers.get(0).getName()).isEqualTo("teacherA");
}
@Test
void namedNativeQueryInJpa() {
//Teacher.findNativeByName 은 안된다.
String nativeQuery = "select * from Teacher where name = :name";
List<Teacher> teachers = em.createNativeQuery(nativeQuery,Teacher.class)
.setParameter("name","teacherA")
.getResultList();
assertThat(teachers.size()).isEqualTo(1);
}
Spring Data Jpa에서는 더 간단하게 사용가능하다.
👍TIP : 꼭 동적변수에는 @Param 어노테이션을 붙여야 한다.
👍TIP2 : 변수명과 찾는 이름이 동일한 경우에는 생략 가능하다.
😊TeacherRepository.java
public interface TeacherRepository extends JpaRepository<Teacher, Long> {
Teacher findById(long id);
List<Teacher> findByNameContains(String name);
//NamedQuery
List<Teacher> findByName(@Param("name") String name);
//NamedNativeQuery
List<Teacher> findNativeByName(@Param("name") String name);
}
😊Test.java
@Test
void namedQuery() {
List<Teacher> teachers = teacherRepository.findByName("teacherA");
assertThat(teachers.size()).isEqualTo(1);
assertThat(teachers.get(0).getName()).isEqualTo("teacherA");
}
@Test
void namedNativeQuery() {
List<Teacher> teachers = teacherRepository.findNativeByName("teacherA");
assertThat(teachers.size()).isEqualTo(1);
assertThat(teachers.get(0).getName()).isEqualTo("teacherA");
}
3. Query Annotation
NamedQuery는 어플리케이션 로딩시점에 에러를 확인 할 수 있다는 장점이 있으나 엔티티 위에 어노테이션으로 작성해야 한다는 부담이 있다.
(여러개면 @NamedQueries 안에 작성 필요하다.)
복잡한 실무에서는 한 번 더 검색을 해야만 찾을 수 있다. 하지만 @Query는 NamedQuery와 같은 기능에 더 간단한 작성으로 구현 가능하다.
(익명의 NamedQuery라고 보면 된다.)
😊TeacherRepository.java
@Query("select t from Teacher as t where t.age > :age")
List<Teacher> findQueryByAgeGreaterThan(@Param("age") int age);
이걸로 선언 끝이다.
😊Test.java
@Test
void findQueryByAgeGreaterThanTest() {
List<Teacher> teachers = teacherRepository.findQueryByAgeGreaterThan(40);
assertThat(teachers.size()).isEqualTo(2);
}
😊Query.java
public @interface Query {
String value() default "";
String countQuery() default ""; // Page에서 countQuery위한 것
String countProjection() default "";
boolean nativeQuery() default false;
String name() default "";
String countName() default "";
}
4. Return Type
🧷 참고 : 공식문서
Spring Data Jpa는 다양한 리턴 타입을 제공한다. 상황에 맞게 원하는 타입을 변환하는작업이 간단하다.
| Return type | Description |
|---|---|
| void | 리턴이 없다. |
|
Primitives Wrapper types |
기본형이나 Wrapper 클래스 다 가능하다. (int, Integer, Long...) |
| T, Optional (one result) | 기본 엔티티 리턴도 가능하다. (여러건시 에러) |
| Collection | List, Collection, Iterator처럼 컬렉션. |
|
Future CompletableFuture |
@Async 와 함께 사용하면 동기화가 가능하다. |
| Page, Slice | 페이징을 위한 객체 리턴이 가능하다. (Pageable 파라미터 필요) |
Page와 Slice 리턴을 알아보자. Page는 count 쿼리가 추가로 실행되고 Slice는 +1 조회로 다음페이지 존재 여부만 알 수 있다.
4-1 Page
Page와 Slice 둘 다 Pageable 인터페이스 구현 객체를 변수로 넘겨주어야 한다.
해당 객체는 PageRequest라는 구현체를 쓰는 것이 일반적인데 정렬까지 쉽게 구현 가능하다.
😊TeacherRepository.java
Page<Teacher> findPageAllBy(Pageable pageable);
기존 문법대로 find~~By 로 조건 없이 조회하였다.
😊Test.java
@Test
void findPageAllBy() {
teacherRepository.deleteAll(); // 기본메서드
List<Teacher> teachers = new ArrayList<>();
for (int i = 0; i < 100; i++) {
teachers.add(new Teacher("tea"+i, i));
}
teacherRepository.saveAllAndFlush(teachers); // 기본 메서드
// 페이지는 0부터 시작이다. 3페이지이고 1페이지당 5개씩, 정렬하여 조회하였다.
PageRequest pr = PageRequest.of(2, 5, Sort.by("age").ascending());
Page<Teacher> teacherPage = teacherRepository.findPageAllBy(pr);
System.out.println("teacherPage = " + teacherPage.getTotalElements());
System.out.println("getTotalPages() = " + teacherPage.getTotalPages());
for (Teacher teacher : teacherPage.getContent()) {
System.out.println("teacher = " + teacher);
}
🔑query
/* select
generatedAlias0
from
Teacher as generatedAlias0
order by
generatedAlias0.age asc */
select
teacher0_.teacher_id as teacher_1_1_,
teacher0_.age as age2_1_,
teacher0_.name as name3_1_,
teacher0_.subject_id as subject_4_1_
from
teacher teacher0_
order by
teacher0_.age asc limit ? offset ?
/* select
count(generatedAlias0)
from
Teacher as generatedAlias0 */
select
count(teacher0_.teacher_id) as col_0_0_
from
teacher teacher0_
count 쿼리까지 추가로 나간 것을 알 수 있다. (count는 자동 성능 최적화 지원)
💻console
teacherPage = 100
teacherPage.getTotalPages() = 20
teacher = Teacher(id=17, name=tea10, age=10, subject=null)
teacher = Teacher(id=18, name=tea11, age=11, subject=null)
teacher = Teacher(id=19, name=tea12, age=12, subject=null)
teacher = Teacher(id=20, name=tea13, age=13, subject=null)
teacher = Teacher(id=21, name=tea14, age=14, subject=null)
4-2 Slice
Slice는 기존 쿼리보다 +1 하여 다음 페이지 존재 여부만 체크한다. (count 없어 성능 유리)
😊TeacherRepository.java
Slice<Teacher> findSliceAllBy(Pageable pageable);
😊Test.java
@Test
void sliceTest() {
// DB에 기본값 저장
teacherRepository.deleteAll();
List<Teacher> teachers = new ArrayList<>();
for (int i = 0; i < 20; i++) {
teachers.add(new Teacher("tea"+i, i));
}
teacherRepository.saveAllAndFlush(teachers);
PageRequest pr = PageRequest.of(3, 4, Sort.by(ASC,"age"));
Slice<Teacher> teacherSlice = teacherRepository.findSliceAllBy(pr);
Slice<TeacherDto> dtos =
teacherSlice.map(t -> new TeacherDto(t.getName(),t.getAge(),""));
for (TeacherDto dto : dtos) {
System.out.println("dto = " + dto);
}
}
🔑query
/* select
generatedAlias0
from
Teacher as generatedAlias0
order by
generatedAlias0.age asc */
select
teacher0_.teacher_id as teacher_1_1_,
teacher0_.age as age2_1_,
teacher0_.name as name3_1_,
teacher0_.subject_id as subject_4_1_
from
teacher teacher0_
order by
teacher0_.age asc limit ? offset ?
💻console
dto = TeacherDto(name=tea12, age=12, subjectName=)
dto = TeacherDto(name=tea13, age=13, subjectName=)
dto = TeacherDto(name=tea14, age=14, subjectName=)
dto = TeacherDto(name=tea15, age=15, subjectName=)
5. Modifying Queries (Bulk Query)
JPA는 변경감지로 조회한 엔티티의 수정을 통해 UPDATE가 이루어진다.
하지만 모든 회원 나이 1살 증가라던가 연봉 10%상승같은 여러건의 업데이트를 실행해야 하는 경우에 여러건의 업데이트를 수행하는 벌크성 쿼리를 제공한다.
예제를 보며 확인해 보자.
😊TeacherRepository.java
@Modifying(clearAutomatically = true)
@Query(value = "update Teacher as t set t.age = :age", nativeQuery = false)
int updateBulkAge(@Param("age") int age);
clearAutomatically 속성은 해당 벌크성 쿼리 실행 후 em.clear() 을 해주는 것이다.
(캐쉬를 비워야 싱크가 맞는다.)
😊Test.java
@Test
void bulkQuery() {
teacherRepository.updateBulkAge(10);
// n+1 문제 발생!!! 패치조인을 해야 한다.
List<Teacher> teachers2 = teacherRepository.findAll();
for (Teacher teacher : teachers2) {
System.out.println("teacher2 = " + teacher);
}
}
🔑query
/* update
Teacher as t
set
t.age = :age */
update
teacher
set
age=?
💻console
••• 😂query
teacher2 = Teacher(id=4, name=teacherA, age=10, subject=Subject(id=1, title=math))
••• 😂query
teacher2 = Teacher(id=5, name=teacherB, age=10, subject=Subject(id=2, title=english))
••• 😂query
teacher2 = Teacher(id=6, name=mathT, age=10, subject=Subject(id=1, title=math))
원하는 결과는 나왔지만 조회 후 출력할 때 n+1문제가 발생했다.
이 경우에는 페치조인을 해야 한다. Spring Data Jpa 에서는 EntityGraph로 페치조인을 쉽게 적용할 수 있다.
6. EntityGraph (fetch join)
Jpa 2.1 버전 이후로 페치 조인을 위한 @EntityGraph 어노테이션과 @NamedEntityGraph을 지원한다.
기존에 있는 findAll 같은 함수나 @Query, naming 자동 생성 함수도 @EntityGraph과 페치조인할 속성만 정의하면 된다.
😊TeacherRepository.java
@EntityGraph(attributePaths = {"subject"})
List<Teacher> findFirstByAgeIsLessThan(int age);
EntityGraph 어노테이션을 선언하고 attributePaths로 페치 조인할 엔티티의 변수명을 지정한다.
(하나면 괄호 생략 가능)
😊Test.java
@Test
void entityGraph(){
teacherRepository.findFirstByAgeIsLessThan(40);
}
🔑query
/* select
generatedAlias0
from
Teacher as generatedAlias0
where
generatedAlias0.age<:param0 */
select
teacher0_.teacher_id as teacher_1_1_0_,
subject1_.subject_id as subject_1_0_1_,
teacher0_.age as age2_1_0_,
teacher0_.name as name3_1_0_,
teacher0_.subject_id as subject_4_1_0_,
subject1_.title as title2_0_1_
from
teacher teacher0_
left outer join
subject subject1_
on teacher0_.subject_id=subject1_.subject_id
where
teacher0_.age<? limit ?
💻console
••• 😂query
teacher2 = Teacher(id=4, name=teacherA, age=10, subject=Subject(id=1, title=math))
••• 😂query
teacher2 = Teacher(id=5, name=teacherB, age=10, subject=Subject(id=2, title=english))
••• 😂query
teacher2 = Teacher(id=6, name=mathT, age=10, subject=Subject(id=1, title=math))
👍TIP : NamedEntityGraph는 Entity에 선언하고 @EntityGraph의 value에 이름을 입력하면 된다. 😊Teacher.java
@Entity
@NamedEntityGraph(name = "Teacher.subject",
attributeNodes = @NamedAttributeNode("subject"))
public class Teacher {
•••
😊TeacherRepository.java
@EntityGraph(value = "Teacher.subject")
Optional<Teacher> findFirstBy();
😊TIP : 지연 여부 확인
// Hibernate 지연 여부 확인
boolean initialized = Hibernate.isInitialized(teacher.getSubject());
System.out.println("[Hibernate] subject is proxy? " + initialized);
// JPA 표준방법으로 확인
PersistenceUnitUtil util = em.getEntityManagerFactory().getPersistenceUnitUtil();
boolean loaded = util.isLoaded(teacher.getSubject());
System.out.println("[Hibernate] subject is proxy? " + initialized);
7. JPA Hint & Lock
JPA Hint는 jpa가 구현체인 hibernate에 전달하는 힌트이다. 여러 속성을 구현체에 전달 할 수 있다.
😊TeacherRepository.java
@QueryHints(value = { @QueryHint(name = "org.hibernate.readOnly", value = "true")})
Optional<Teacher> findHintById(Long id);
😊Test.java
@Test
void findHintById() {
teacherRepository.save(new Teacher("test", 22));
em.flush();
em.clear();
Optional<Teacher> hintTea = teacherRepository.findHintById(teacher.getId());
hintTea.get().setAge(33);
em.flush();
em.clear();
Optional<Teacher> hintById = teacherRepository.findHintById(teacher.getId());
assertThat(hintById.get().getAge()).isEqualTo(22); // 안바뀜
}
ReadOnly 속성을 true로 주니 변경 감지가 동작하지 않아 update 쿼리가 실행되지 않았다.
DB Lock은 @Lock 어노테이션을 통해 쉽게 설정 할 수 있다.
😊TeacherRepository.java
@Lock(LockModeType.PESSIMISTIC_WRITE)
Optional<Teacher> findLockByName(String name);
8. Custom Repository
Spring Data JPA Repository는 인터페이스만 정의하고 구현체는 스프링이 자동 생성한다.
만약 Spring Data JPA가 제공하는 인터페이스를 직접 구현하려면 구현해야 하는 기능이 너무 많다.
하지만 원하는 메서드만 직접 구현할 수 있게 해 놓았다.
😊CustomRepository.java
public interface CustomRepository {
Teacher findCustomById(Long id);
}
😊CustomRepositoryImpl.java
@Repository
@Transactional
public class CustomRepositoryImpl implements CustomRepository {
@Autowired
EntityManager em;
@Override
public Teacher findCustomById(Long id) {
System.out.println("========================");
System.out.println("now CustomRepositoryImpl");
System.out.println("========================");
return em.createQuery("select t from Teacher as t where t.id = :id",Teacher.class)
.setParameter("id",id)
.getSingleResult();
}
}
인터페이스를 만들고 구현체는 인터페이스 이름 뒤에 Impl을 붙여야 Spring Data Jpa가 인식한다.
😊TeacherRepository.java
public interface TeacherRepository extends JpaRepository<Teacher, Long>, CustomRepository {
기존 TeacherRepository에 다중 상속을 받으면 CustomRepository의 기능은 구현체인 CustomRepositoryImpl에 선언된 대로 진행된다.
😊Test.java
@Test
void findCustomRepo() {
Teacher teacher = new Teacher("test", 22);
teacherRepository.save(teacher);
em.flush();
em.clear();
Teacher customById = teacherRepository.findCustomById(teacher.getId());
System.out.println("customById = " + customById);
}
💻console
========================
now CustomRepositoryImpl
========================
••• Query
customById = Teacher(id=7, name=test, age=22, subject=null)
해당 CustomRepositoryImpl Print가 출력 된 걸 알 수 있다.
8. JPA Entity Lifecycle Event
JPA가 동작 할 때 엔티티의 라이프사이클동안 실행할 수 있는 이벤트가 있다.
Spring Data JPA에서는 주석을 활용하여 이벤트에 쉽게 접근하고 비즈니스 로직을 활용할 수 있다.
엔티티 자체에 대한 메서드에 주석을 추가하고 엔티티 리스너를 이용하면 된다.
| Annotation | Description |
|---|---|
| @PrePersist | persist 하기 전 |
| @PostPersist | persist 한 뒤 |
| @PreRemove | 엔티티 삭제 전 |
| @PostRemove | 엔티티 삭제 뒤 |
| @PreUpdate | 엔티티 업데이트 전 |
| @PostUpdate | 엔티티 업데이트 후 |
| @PostLoad | 엔티티가 로드 된 후 (select 이후) |
예를 들어 확인해보자.
😊Teacher.java
@PrePersist
void prePersist() {
log.info("😊 prePersist start!!!");
}
@PostPersist
void postPersist() {
log.info("😊 postPersist start!!!");
}
@PreRemove
void preRemove() {
log.info("😊 preRemove start!!!");
}
@PostRemove
void postRemove() {
log.info("😊 postRemove start!!!");
}
@PreUpdate
void preUpdate() {
log.info("😊 preUpdate start!!!");
}
@PostUpdate
void postUpdate() {
log.info("😊 postUpdate start!!!");
}
@PostLoad
void postLoad() {
log.info("😊 postLoad start!!!");
}
😊Test.java
@Test
void lifecycleTest () {
System.out.println("😊 lifecycleTest start!!");
Teacher teacher = new Teacher("testT", 100);
teacherRepository.save(teacher);
em.flush();
em.clear();
Teacher findTeacher = teacherRepository.findById(teacher.getId()).get();
findTeacher.setName("testT2");
em.flush();
em.clear();
Teacher findTeacher2 = teacherRepository.findById(findTeacher.getId()).get();
teacherRepository.delete(findTeacher2);
em.flush();
em.clear();
}
💻console
😊 lifecycleTest start!!
😊 prePersist start!!!
😊 postPersist start!!!
😊 postLoad start!!!
😊 preUpdate start!!!
😊 postUpdate start!!!
😊 postLoad start!!!
😊 preRemove start!!!
😊 postRemove start!!!
해당 이벤트를 적용해서 엔티티에 생성시간, 수정시간, 생성자, 수정자를 각각 넣어 줄 수 있다.
9. Auditing
JPA에서는 각 이벤트에 특정한 행위를 할 수 있는 Audit을 제공한다.
보통 DB에 들어가는 생성시간, 생성자, 수정시간, 수정자 등 공통으로 데이터가 삽입, 변경될 때 원하는 옵션을 할 수 있다.
- Entity에 @EntityListeners(AuditingEntityListener.class) 삽입한다.
- @EnableJpaAuditing을 스프링 부트 어노테이션과 같이 작성한다.
- AuditorAware를 리턴하는 Bean을 만든다 (생략시 Date만 작동가능)
예를 들어 보자.
😊BaseEntity.java
@Getter @Setter
@EntityListeners(AuditingEntityListener.class)
@MappedSuperclass
public abstract class BaseEntity {
@CreatedDate
@Column(updatable = false)
protected LocalDateTime createDate;
@CreatedBy
@Column(updatable = false)
protected String createName;
@LastModifiedDate
protected LocalDateTime lastModifiedDate;
@LastModifiedBy
protected String lastModifiedName;
}
생성자, 생성시간, 수정자, 수정시간은 운영에서 데이터 추적이 가능한 중요한 요소이므로 Spring Data Jpa에서는 어노테이션으로 쉽게 쓸 수 있게 제공한다.
다만 CreateBy와 LastModifiedBy는 AuditorAware 를 리턴하는 빈을 구현해야 한다.
😊Teacher.java
@Entity
public class Teacher extends BaseEntity {
•••
}
상속받아 해당 기능을 쉽게 사용 가능하다.
😊DataJpaConfig.java
@Configuration
public class DataJpaConfig {
@Bean
public AuditorAware<String> auditorProvider() {
return () -> Optional.of(UUID.randomUUID().toString());
}
}
예제로 UUID를 받았지만 실무에서는 RequestContextHolder (스프링 전역에서 Request를 가져올 수 있다.)
등을 사용하여 세션에서 유저 아이디를 가져와 넣으면 된다.
😊SpringDataJpaApplication.java
@EnableJpaAuditing
@SpringBootApplication
public class SpringDataJpaApplication {
public static void main(String[] args) {
SpringApplication.run(SpringDataJpaApplication.class, args);
}
}
✨@EnableJpaAuditing를 사용해야만 Auditing기능이 작동한다.
👍TIP1 : @EntityListeners(AuditingEntityListener.class)를 생략하고 Spring Data Jpa가 제공하는 이벤트를 엔티티 전체에 적용하려면 orm.xml에 다음과 같이 등록하면 된다.
👍TIP2 : @EntityListeners(AuditingEntityListener.class) 안의 AuditingEntityListener 대신에 사용자가 직접 정의한 클래스를 넣을 수 있다.
해당 클래스는 Entity Lifecycle Event의 어노테이션 (ex @PrePersist) 등을 사용하여 기능을 정의할 수 있다.
😊META-INF/orm.xml
<?xml version=“1.0” encoding="UTF-8”?>
<entity-mappings xmlns=“http://xmlns.jcp.org/xml/ns/persistence/orm”
xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
xsi:schemaLocation=“http://xmlns.jcp.org/xml/ns/persistence/
orm http://xmlns.jcp.org/xml/ns/persistence/orm_2_2.xsd”
version=“2.2">
<persistence-unit-metadata>
<persistence-unit-defaults>
<entity-listeners>
<entity-listener
class="org.springframework.data.jpa.domain.support.AuditingEntityListener”/>
</entity-listeners>
</persistence-unit-defaults>
</persistence-unit-metadata>
</entity-mappings>
👍TIP3 : EntityListeners에서 @Autowired가 동작하지 않는 이유
EntityListeners로 등록한 클래스는 Spring IOC 컨테이너의 관리 대상이 아니기 때문이다.
ApplicationEvent를 상속받아 DI 전 우선 주입으로 해결할 수 있다.
참고 : 김찬정블로그
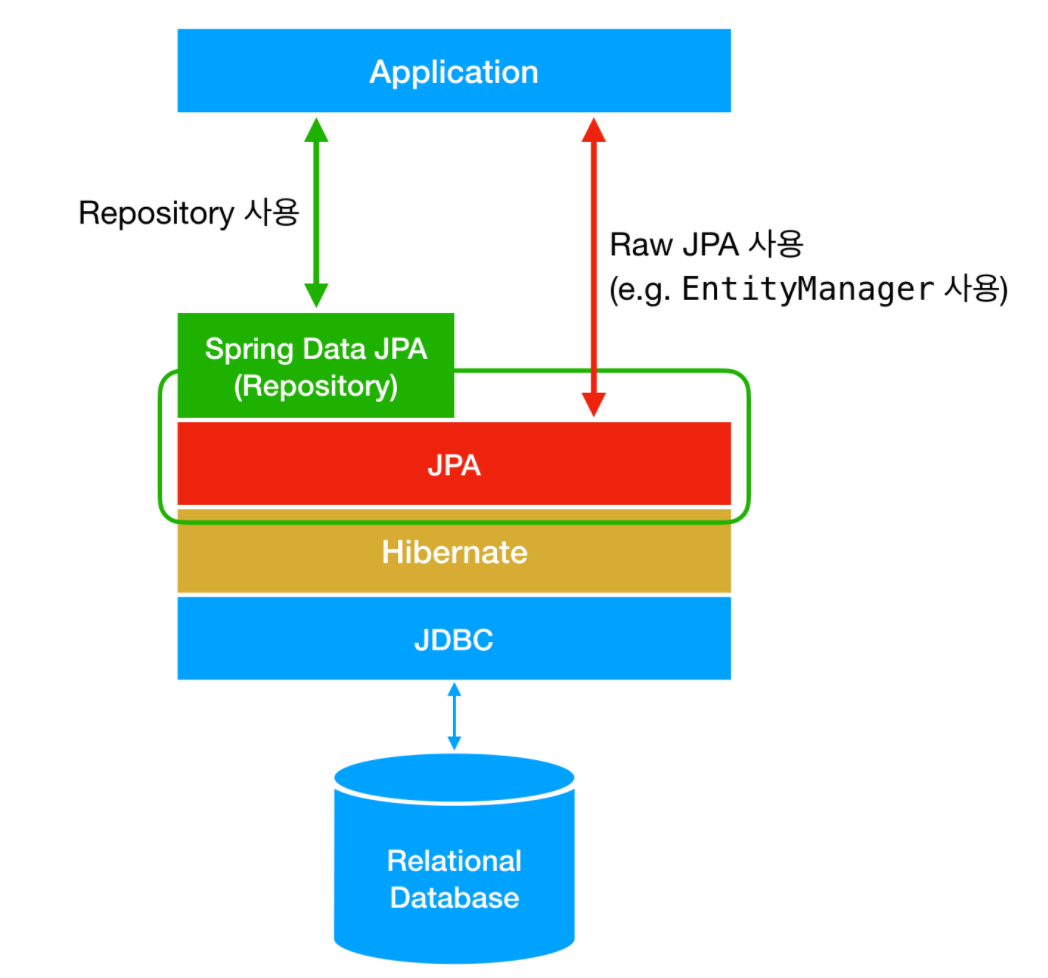
How does Spring Data JPA Repository work?
Spring Data JPA는 JPA를 추상화하여 사용하기 간편하게 만든 것이다. 대부분의 경우 EntityManager를 직접 다루지 않는다. (물론 사용할 수도 있다.)
JPA를 추상화한 Repository와 여러 어노테이션을 기반한 기능으로 JPA를 보다 간단하게 사용가능하다.
위의 예제에서 JpaRepository를 상속받고 findByNameContains() 라는 메소드 명만 지었는데 실제로 동작이 되었다.
🤔 구현체를 알아 보자.
•••
System.out.println("teacherRepository = " + teacherRepository.getClass().getName());
💻console
teacherRepository = com.sun.proxy.$Proxy83
class를 보니 프록시에서 만들어 준 구현체를 사용하고 있다. 디버그로 확인해보자.

spring boot의 기본 구현체는 SimpleJpaRepository 이다. 분석해보자.
😊SimpleJpaRepository.java
@Repository
@Transactional(
readOnly = true // 각각 메소드마다 @Transactional 따로 거는 듯하다. 전체적인 dirty checking 생략때문에 하는듯
)
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID> {
private static final String ID_MUST_NOT_BE_NULL = "The given id must not be null!";
private final JpaEntityInformation<T, ?> entityInformation; // T인 엔티티 정보
private final EntityManager em; // 엔티티 매니저
private final PersistenceProvider provider; // Hibernate 같은 공급자
@Nullable
private CrudMethodMetadata metadata;
private EscapeCharacter escapeCharacter; // 기본 \이다.
// Repository 구현체에서 엔티티 매니저를 사용한다.
public T getById(ID id) {
Assert.notNull(id, "The given id must not be null!");
return this.em.getReference(this.getDomainClass(), id);
}
•••
@Transactional
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (this.entityInformation.isNew(entity)) {
this.em.persist(entity); // 새로운 객체면 persist 아니면 merge 한다.
return entity;
} else {
return this.em.merge(entity);
}
}
// 기본적인 Query는 Criteria를 사용한다.
protected <S extends T> TypedQuery<S> getQuery(@Nullable Specification<S> spec, Class<S> domainClass, Sort sort) {
CriteriaBuilder builder = this.em.getCriteriaBuilder();
CriteriaQuery<S> query = builder.createQuery(domainClass);
Root<S> root = this.applySpecificationToCriteria(spec, domainClass, query);
query.select(root);
if (sort.isSorted()) {
query.orderBy(QueryUtils.toOrders(sort, root, builder));
}
return this.applyRepositoryMethodMetadata(this.em.createQuery(query));
}
기본적인 JPA 구현체는 엔티티매니저를 사용하고 Criteria와 em.createQuery() 로 쿼리를 만들어 준다.
사용자 Repository 세팅은 JpaRepositoryFactory에서 한다.
😊JpaRepositoryFactory.java
//RepositoryFactorySupport 추상 클래스를 상속받아 JpaRepositoryFactory 에서 getTargetRepository 으로 세팅한다.
protected final JpaRepositoryImplementation<?, ?> getTargetRepository(RepositoryInformation information) {
JpaRepositoryImplementation<?, ?> repository = this.getTargetRepository(information, this.entityManager);
repository.setRepositoryMethodMetadata(this.crudMethodMetadataPostProcessor.getCrudMethodMetadata());
repository.setEscapeCharacter(this.escapeCharacter);
return repository;
}
👍TIP : 엔티티 상태 탐지 전략 (신규 or 기존)
- Version-Property and Id-Property inspection (default): 기본적으로 Spring Data JPA는 1. Version-Property를 탐지하고 2. @ID를 탐지한다. (✨null이면 새로운 엔티티)
- Implementing Persistable: 만약 엔티티가 Persistable을 구현했다면 isNew() 라는 메서드를 정의하여 판별한다.
- Implementing EntityInformation: SimpleJpaRepository를 상속받는 클래스를 생성하고 getEntity를 Override하여 커스터마이징 가능하다. (JpaRepositoryFactory 구현도 Bean 등록)
Reference
공식 https://spring.io/projects/spring-data-jpa#overview
가이드 https://spring.io/guides/gs/accessing-data-jpa/
Hibernate 가이드
ERROR CODE
- TransactionRequiredException : No EntityManager with actual transaction
💻console
javax.persistence.TransactionRequiredException:
No EntityManager with actual transaction available for current thread
- cannot reliably process 'persist' call
•••
가장 많이 하는 실수이다. test 클래스를 만들 때 @Transactional을 붙이지 않아 에러났다.
- IllegalArgumentException: Could not locate named parameter
😊Test.java
@Test
void namedNativeQueryInJpa() {
List<Teacher> teachers = em.createNativeQuery("Teacher.findNativeByName",Teacher.class)
.setParameter("name","teacherA")
.getResultList();
assertThat(teachers.size()).isEqualTo(1);
}
💻console
java.lang.IllegalArgumentException: Could not locate named parameter [name], expecting one of []
at org.hibernate.query.internal.ParameterMetadataImpl.getNamedParameterDescriptor(ParameterMetadataImpl.java:229)
at org.hibernate.query.internal.ParameterMetadataImpl.getQueryParameter(ParameterMetadataImpl.java:198)
•••
em.createNativeQuery에서 정의된 이름이 아니라 직접 쿼리를 넣으니 테스트 성공했다.
3.ClassCastException : cannot be cast to class
java.lang.ClassCastException: class [Ljava.lang.Object;
cannot be cast to class com.example.springdatajpa.entity.Teacher
([Ljava.lang.Object; is in module java.base of loader 'bootstrap';
com.example.springdatajpa.entity.Teacher is in unnamed module of loader 'app')
em.createNativeQuery에서 두번째 인자로 리턴 클래스를 주지 않아 발생했다.
- IllegalStateException: Paging query needs to have a Pageable parameter!
Caused by: java.lang.IllegalArgumentException:
Paging query needs to have a Pageable parameter!
Offending method public abstract org.springframework.data.domain.Page
com.example.springdatajpa.repository.TeacherRepository.findPageAll()
Page로 리턴받았는데 Pageable 파라미터를 받지 않았다.(Page, Slice리턴은 필수로 받아야한다.)
댓글남기기